ComputerVisionFinal
Sports Images Classifier
CSE 455 - Computer Vision
Final Project - Garrett Devereux - University of Washington (Spring 2022)
 Problem Description
Problem Description
Sports have always been an important part of my life, providing me with the motivation to constantly improve my skills and health, help build relationships and connections with others, and teach me lessons about teamwork and perseverance that carry over into my other pursuits. My project directly relates to this passion and aims to analyze a variety of images containing sports and classify them using neural networks and computer vision techniques. My data set comes from this Kaggle Competition which contains over 14,000 images from 100 different sports. In my project, I explore a variety of different model architectures and data processing and training techniques such as data augmentation and transfer learning. I then compare and contrast each model’s performance and see how they do in the real world with pictures of myself playing sports throughout the years.

 Preexisting Work
Preexisting Work
All of the code in this repository is brand new for this project, using Professor Joseph Redmon's PyTorch tutorial as inspiration and utilizing the Kaggle Sports Images Dataset. The entirety of the implementation resides in Final_Project.ipynb as a Colab notebook, and contains comprehensive documentation. The notebook provides a step-by-step walk though of the project as well as an analysis of the results. This site only synthesizes the information found in the notebook.
 Project Files
Project Files
All files from this project can be found in the Repository. The video presentation is linked at the top of this webpage and can be found here.
This Project includes a Colab notebook with all of the code, a dataset folder, and a results folder.
Code:
- Final_Project.ipynb - Includes all of the implementation for the project with a detailed walkthrough and analysis.
Dataset: in the sportsImages/ folder
- sportsImages/models/ - Contains all of the trained models produced throughout the project, as well as .csv files showing each model's prediction versus the actual label on the entire test set. *Note: the simple model was too large of a file to handle, so it is not included.
- sportsImages/realworld/ - Contains twenty different images of myself playing sports over the years. Used to check each model's performance in the real world.
- sportsImages/test/ - Contains all 500 images of the test set. Inside /test/ are 100 folders labeled with the corresponding sport, and then inside each sport folder is five images.
- sportsImages/train/ - Contains all 13572 images of the training set. Inside /train/ are 100 folders labeled with the corresponding sport, and then inside each sport folder is on average 136 images.
- sportsImages/valid/ - Contains all 500 images of the validation set. Inside /valid/ are 100 folders labeled with the corresponding sport, and then inside each sport folder is five images.
- sportsImages/class_dict.csv - A .csv file containing an entry for each sport in the form: index, sport name, height, width, scale. This allows us to take a prediction index and map it to a class name.
Results/:
- Results/ComparisonResults/ - Includes 11 images for the validation comparison with each model's prediction, and twenty images for the real world comparison with each of the five model's predictions.
- Results/DatasetExampleImages/ - Includes two examples of a batch of 32 images from the training set with different augmentations applied.
- Results/TrainingResults/ Contains a graph of the training loss for each of the five models over 20 epochs, as well as a .txt file with the exact loss after every 10 batches during training.
Other:
- website/ - Includes all assets for the website.
- README.md - This document. Includes the code for the website.
- _.config.yml - Config file for the webpage.
 Dataset and Preprocessing
Dataset and Preprocessing
The sportsImages dataset contains images from 100 different sports from air hockey to wingsuit flying. Reference the class_dict.csv for all of the classes. There are 13572 images in the training set, and 500 in both the test and validation set. The images are 3x224x224 which I then size down to 3x150x150 to help reduce the dimensions and train faster. This greatly reduces the size of the simple model, which is still too big to store on github. On my first attempt of training the models, I performed a resize, random crop, random horizontal flip, random rotation, and then added gaussian noise to each image. 32 of these images looked like:

After training the models for the first time with the above augmentation, I found the test accuracy was terrible, with the simple model acheiving around 10% test accuracy, 50% for the convolutional model, and only 37% for the pretrained resnet18. It was clear that this augmentation was doing too much alteration from the test set and was hurting the performance much more than it was helping. So, after experimenting with a variety of other augmentations, I finally found the right mix of Gaussian noise and rotation range to get the following:

In order to load this dataset and perform the augmentations, view the sections 'Loading the Dataset', 'Data Augmentation', and 'Understanding the Dataset' in Final_Project.ipynb. These sections will also provide more in depth explanations of how to access and manipulate images, as well as how to print out batches like the two above.
 Approach
Approach
Building networks for classification
SimpleNet
I first approached the problem by building a very simple model to get a baseline accuracy score and an idea of how complex the dataset is to learn. This simple model is called SimpleNet and is a very vanilla Neural Network with a single hidden layer using Leaky-Relu activation. As the input images are augmented down to (3 x 150 x 150) the input size will be 67500. Additionally, since the model is making predictions for 100 classes, the final layer needs to be of size 100. With a hidden layer size of 512, there will be 34,611,200 (67500x512 + 512x100) different weights in the model.
ConvNet
As a better approach, I next worked to take advantage of the structure of images with convolutions, batch normalization, and pooling to greatly reduce the size of the network while increasing its power. Here I referenced Professor Redmon's demo lecture on Convolutional Neural Networks and chose to use the Darknet Architecture. As my images were much larger than the example (3x150x150 vs 3x64x64), I worked to tweak the strides and sizes of the different convolutions to produce a reasonably sized outcome. This resulted in five convolutions mapping the input image to the following sizes: (3x150x150)->(16x50x50)->(32x25x25)->(64x13x13)->(128x7x7)->(256x4x4). Additionally, I changed the final output layer to size 100 to fit the number of classes in my dataset.
ResNetv1
To continue to increase model performance, I then moved to using transfer learning on pretrained networks. As a first try of this, I again followed Redmon's demo and fit the pretrained resnet18 model to my own dataset. This required me to change the final fully connected layer to map to 100 classes rather than the over 20,000 categories of ImageNet.
ResNetv2 and EffNet
Finally, I wanted to build a model better than all of the above by taking advantage of the techniques that worked and continuing to tweak the parameters and process. As the Resnet transfer learning worked the best, I first wanted to use the same model with different data augmentation to see if I could find transformations that would produce better results. Using the exact same resnet18 architecture referenced above, I tried several new augmentations, adding more and less rotation and noise, removing the flipping and cropping of images, and in the end, I found that keeping the horizontal image flips, removing the rotations and noise, and normalizing the image before putting it through the network worked the best. With this knowledge, I then again took advantage of transfer learning to bring in the Efficientnet_b0 with the new set of augmentations.
Models Implemented:
- SimpleNet
- 1 Hidden Layer with Leaky-Relu Activation
- Structure:
- Linear(67500, 512)
- Linear(512, 100)
- ConvNet
- DarkNet Architecture: 5 Convolutional Layers with batch normalization and a linear layer
- Structure:
- Conv2d(3, 16, 3, stride=3, padding=1)
- BatchNorm2d(16)
- Conv2d(16, 32, 3, stride=2, padding=1)
- BatchNorm2d(32)
- Conv2d(32, 64, 3, stride=2, padding=1)
- BatchNorm2d(64)
- Conv2d(64, 128, 3, stride=2, padding=1)
- BatchNorm2d(128)
- Conv2d(128, 256, 3, stride=2, padding=1)
- BatchNorm2d(256)
- Linear(256, 100)
- ResNetv1 and ResNetv2
- Structure:
- EffNet
- Structure:
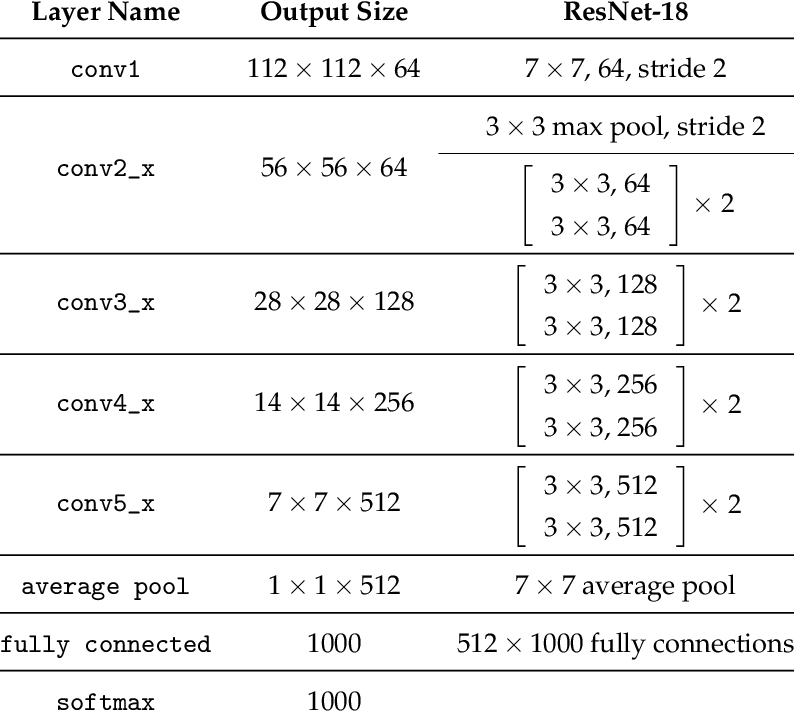
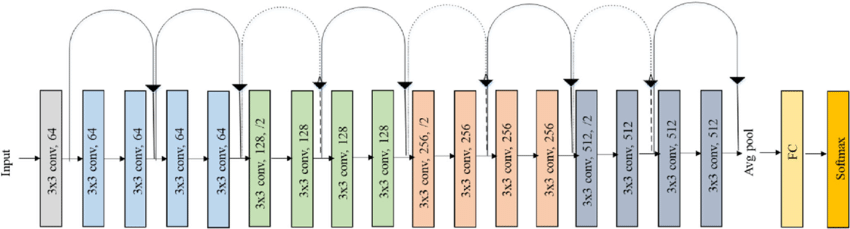
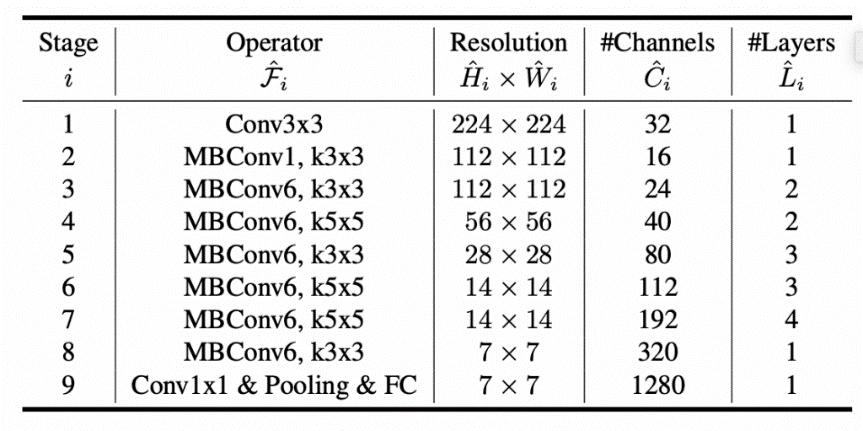
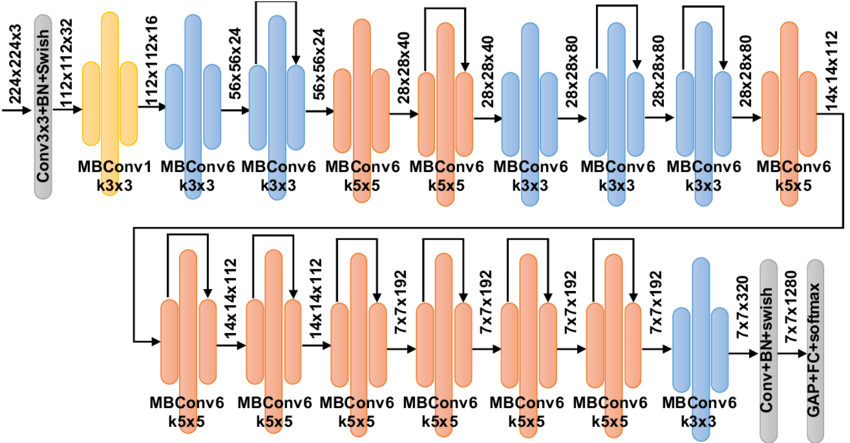
For futher reference, each of these models is implemented in Final_Project.ipynb with full explanation and results.
 Results
Results
After training the models several times with different parameters, I ended with the following results:
SimpleNet:
20 Epochs, Learning Rate schedule: {0:0.01, 15: 0.001}, Batch Size: 128.
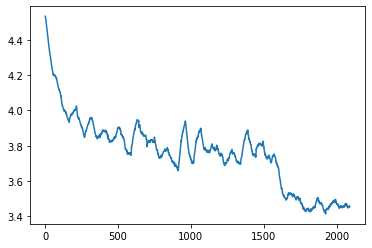
Performance: Training Loss ended at 3.4. 20.2% Testing Accuracy. Predictions versus Actual labels.
ConvNet:
20 Epochs, Learning Rate schedule: {0:0.1, 5:0.01, 15: 0.001}, Batch Size: 128.
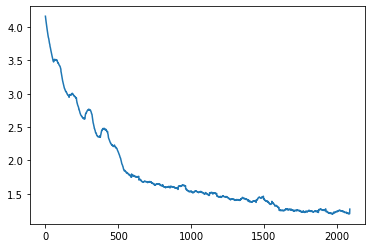
Performance: Training Loss ended at 1.2. 66.4% Testing Accuracy after 20 epochs. 67.0% accuracy after 17 epochs. Predictions versus Actual labels.
ResNetv1:
20 Epochs, Learning Rate schedule: {0:0.1, 5:0.01, 15: 0.001}, Batch Size: 128.
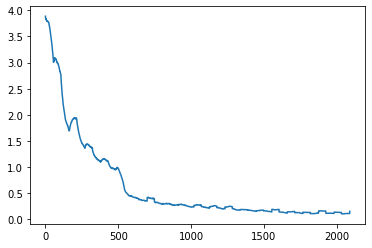
Performance: Training Loss ended at 0.1. 92.2% Testing Accuracy after 20 epochs. Predictions versus Actual labels.
ResNetv2:
20 Epochs, Learning Rate schedule: {0:0.1, 5:0.01, 15: 0.001}, Batch Size: 128.
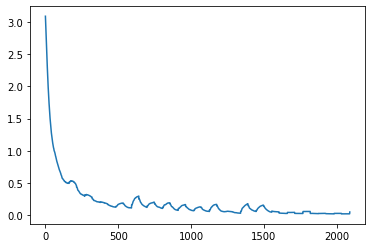
Performance: Training Loss ended at 0.015. 94.6% Testing Accuracy after 20 epochs. Predictions versus Actual labels.
EffNet:
20 Epochs, Learning Rate schedule: {0:0.1, 5:0.01, 15: 0.001}, Batch Size: 128.
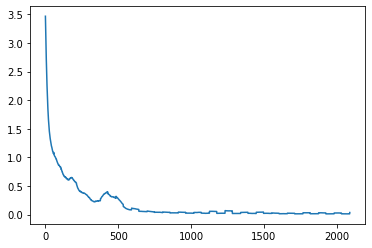
Performance: Training Loss ended at 0.018. 95.6% Testing Accuracy after 20 epochs. 95.8% accuracy after 17 epochs. Predictions versus Actual labels.
Overall, the SimpleNet achieved 20.2% testing accuracy, the ConvNet hit 67.0%, ResNetv1 was at 92.2%, ResNetv2 increased to 94.6%, and EffNet ended at 95.8% accuracy.
 Comparison
Comparison
Validation Comparison
After spending all of this time training the models, I wanted to see what each model learned by comparing and contrasting how each one interpreted different images. By checking this, we could see if the models generally agreed, or if they failed how similar their incorrect prediction was to the correct one. I also thought it would be interesting to see if the pretrained models would ever disagree. Here are the results I found when running each model on a random batch of validation photos:



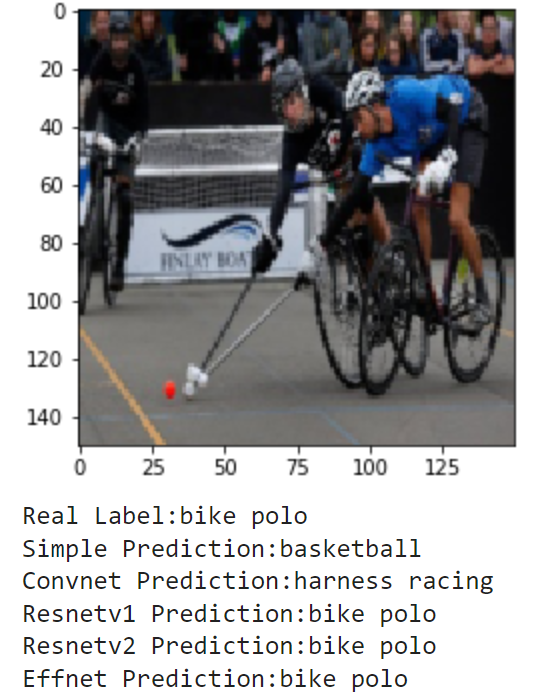
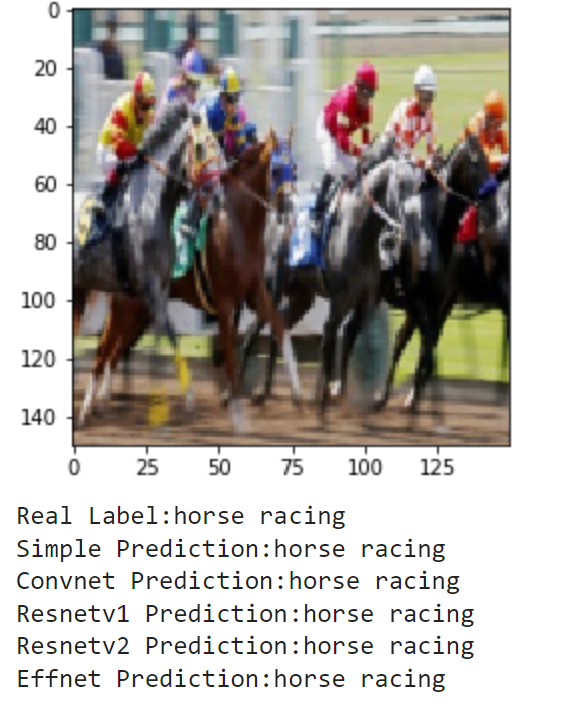




Overall, these results were very consistent with the testing accuracy. SimpleNet only got two out of the nine correct, identifying horse racing and basketball. Every other model was also able to correctly identify these images. For the images it missed, it seemed to have only learned background colors, such as its choice of water polo for pole vault or figure skating men for canoe slalom. The ConvNet was also consistent with the testing accuracy, getting six out of nine correct. For the majority of the images, the trend seemed to be the three pretrained models getting it right, and ConvNet being hit or miss. For example, it is able to correctly identify many that SimpleNet failed at such as bowling, pole vault, and canoe slalom but still makes some poor guesses like judo for shuffleboard and bungee jumping for golf. Next, the three pretrained models all achieved similar results. Interestingly, none of the models were able to get the first photo of horseshoe pitching. The frisbee guess makes a lot of sense, but it goes to show the models are not perfect. Additionally, these models disagree on the pole vault photo, where RestNetv2 guesses high jump. This is a very small mistake as the sports are very close, but it is interesting to see that each model learned different features.
Real World Comparison
Finally, I wanted to see how the models could do off in the real world. I compiled the set of images realworld which contains 20 images of me doing a bunch of different activities. These include photos of me playing football and baseball in high school (and even T-ball), kayaking, paddle boarding and surfing, and other images of me and my friends posing for a photo on a basketball court, football field, or golf course. These photos have no labels, and some don't even match a sport, but we can still examine how the models make their predictions. Here are the results:





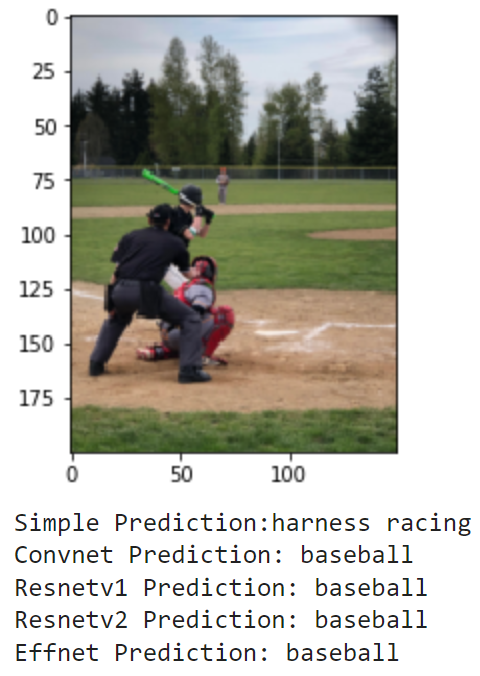






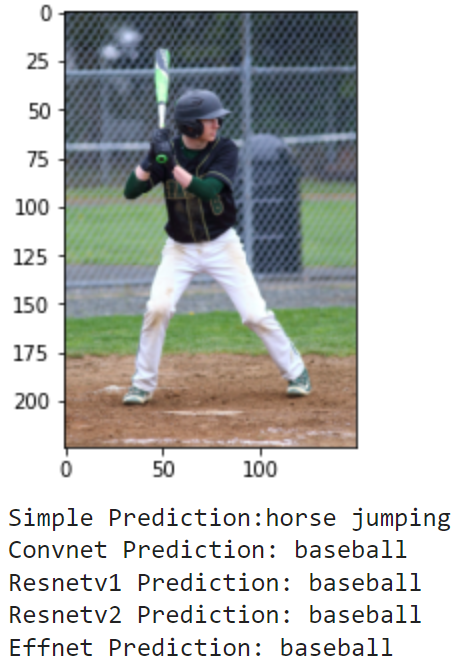
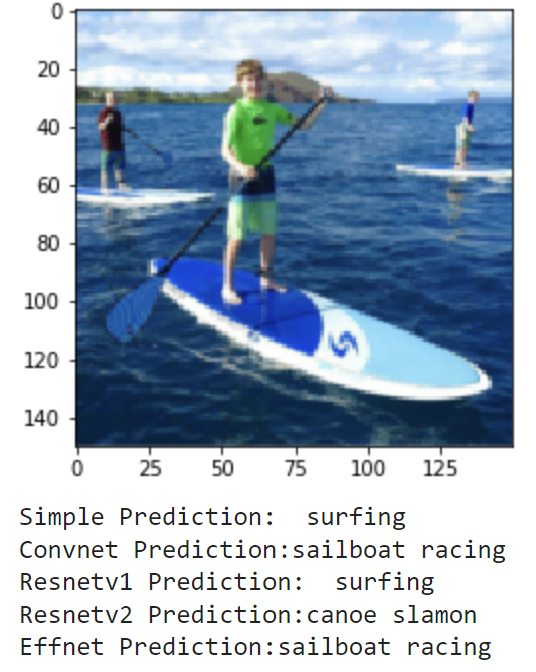
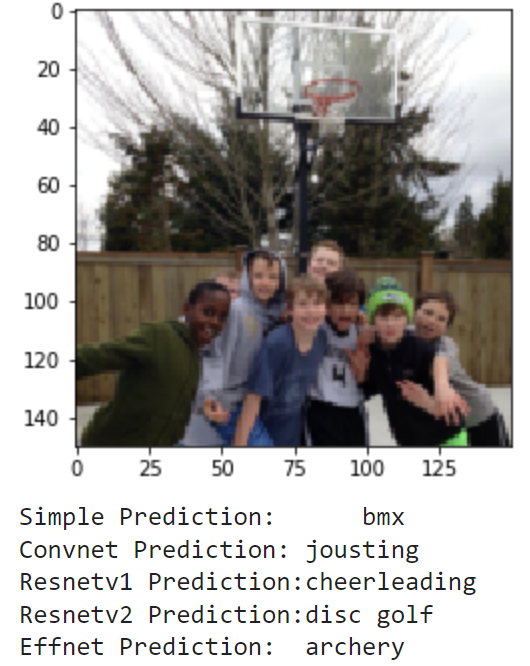
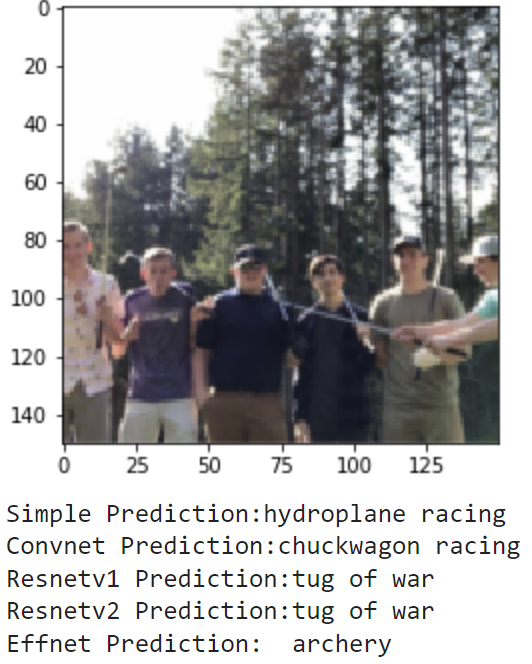
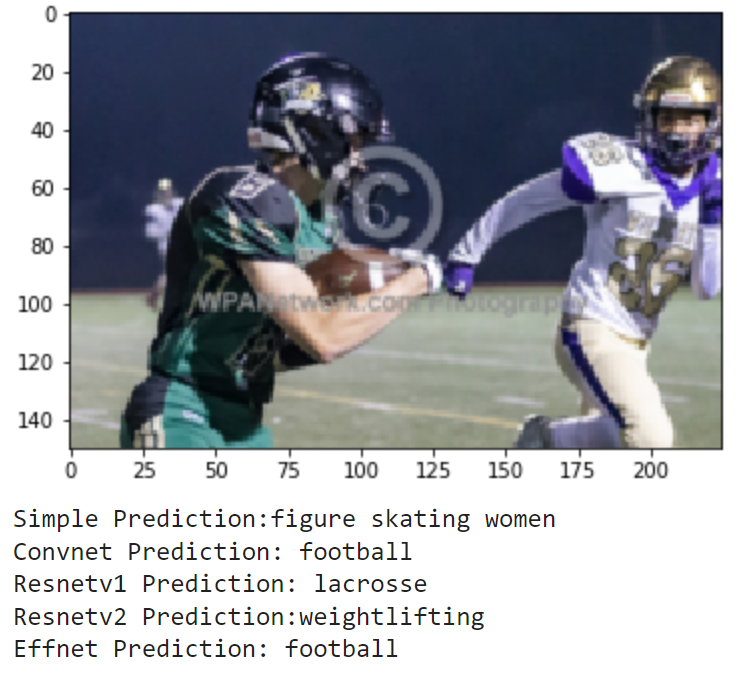
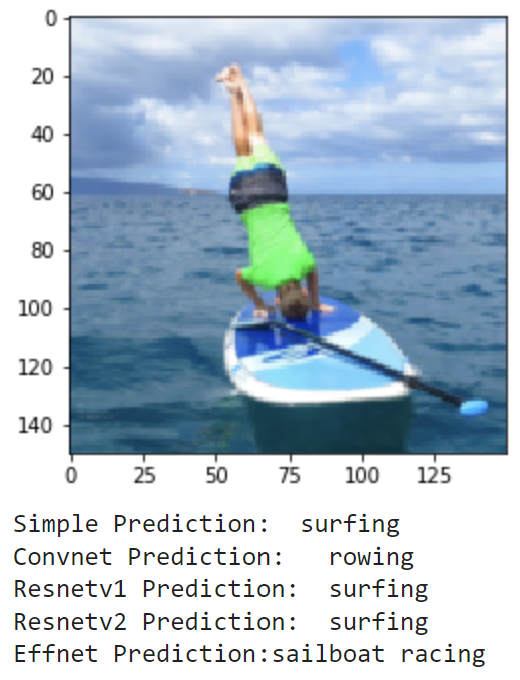
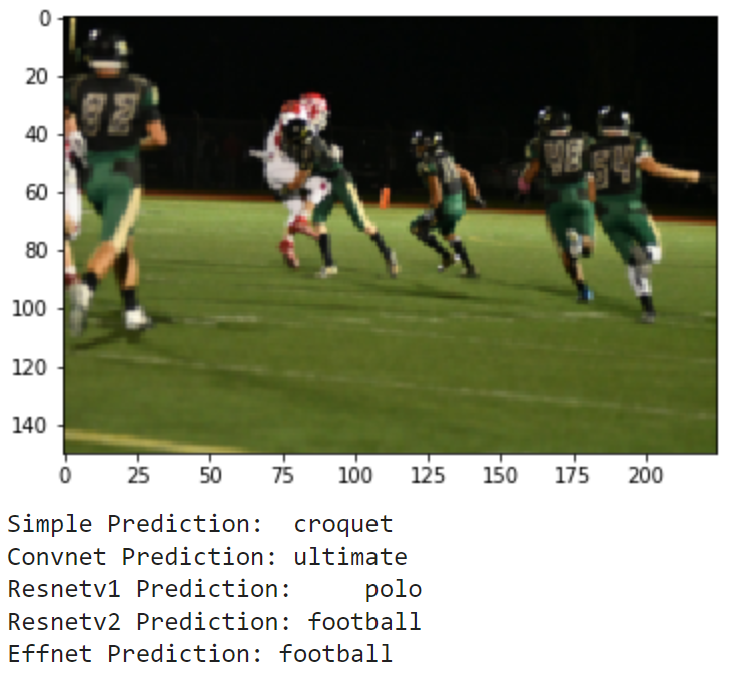
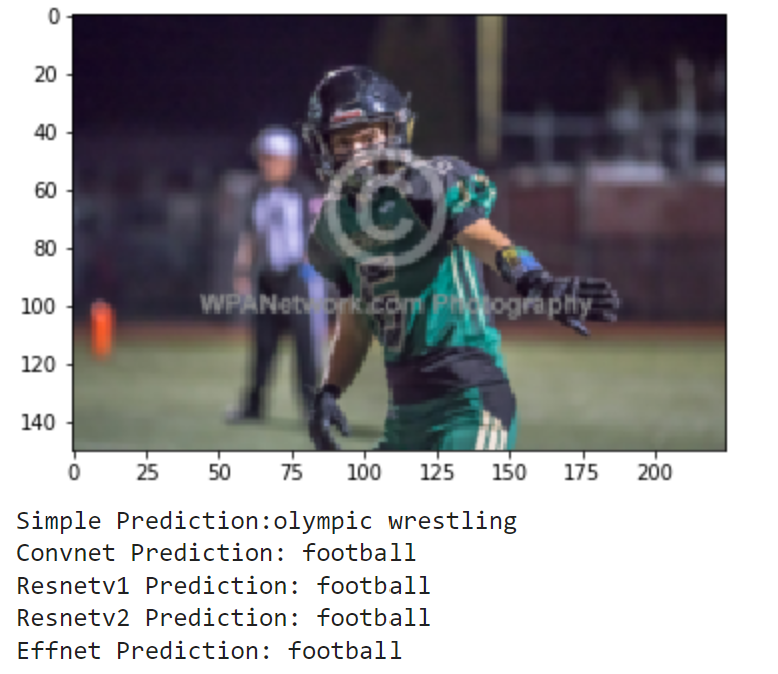
As these images are much different from the training and testing sets, it makes sense that the models don't do great. It seems that most of the action shots are classified pretty well by the models, but there is a lot of confusion for the photos where I am just standing and posing. Overall, it is really interesting to see how each model's learning transfers to a different set in the real world.
Note: See the 'Comparison of the Models', 'Comparison Function', 'Compare on Validation', and 'Real World Application' in Final_Project.ipynb for a full explanation as well as how the code was implemented to aquire these results.
 References
References
Joseph Redmon, 'iPynb Tutorial Series'. [Online].
Available: https://courses.cs.washington.edu/courses/cse455/22sp/
Gerry's Kaggle Dataset, '100 Sports Image Classification'. [Online].
Available: https://www.kaggle.com/datasets/gpiosenka/sports-classification?resource=download
Credits
Garrett Devereux